covid <- read.table(file="https://raw.githubusercontent.com/emrahkirdok/ybva/main/data/covid.txt",sep =" ",header = TRUE)18 Örnek bir veri analizi
Bu döküman kapsamında, farklı veri yükleme senaryoları gösterilecektir. Hepsinin farklı ayraç (sep) değerleri vardır.
18.1 Covid verisi yükleme
Aşağıda gösterilen veriyi read.table() fonksiyonu ile okuyoruz.
Yüklediğimiz verinin boyutlarını geri döndüren kodu yazalım:
#boyutları geri döndüren kod
dim(covid)[1] 127 3#sütun isimlerini geri döndüren kod
colnames(covid)[1] "tarih" "toplam_vaka" "gun" Yüklediğimiz verinin ilk 5 satırını geri döndüren kodu yazalım:
covid [1:5, ] tarih toplam_vaka gun
1 2019-12-31 27 1
2 2020-01-01 27 2
3 2020-01-02 27 3
4 2020-01-03 44 4
5 2020-01-04 44 518.2 Mikrobiyal meta veri yükleme
microbial <- read.table(file = "https://raw.githubusercontent.com/emrahkirdok/ybva/main/data/microbial-metadata.txt", sep = "\t", header = TRUE)Verimizin içindeki condition(koşul ya da durum) sütünuna uluşmak için gereken kodu yazalım:
table(microbial$condition)
Healthy Periodontitis
12 10 18.3 Kalp sağlığı verisi yükleme
Aşağıda gösterilen veriyi read.table() fonksiyonu ile okuyoruz.
veri <- read.table(file="https://raw.githubusercontent.com/emrahkirdok/ybva/main/data/healthcare-dataset-stroke-data.csv",sep ="," , header = TRUE)Yüklediğimiz verinin boyutlarını geri döndüren kodu ve sütun isimlerini geri döndüren kodu yazalım:
#boyutları geri döndüren kod
dim(veri)[1] 5110 12#sütun isimlerini geri döndüren kod
colnames(veri) [1] "id" "gender" "age"
[4] "hypertension" "heart_disease" "ever_married"
[7] "work_type" "Residence_type" "avg_glucose_level"
[10] "bmi" "smoking_status" "stroke" Yüklediğimiz verinin ilk 5 satırını geri döndüren kodu yazalım:
veri [1:5, ] id gender age hypertension heart_disease ever_married work_type
1 9046 Male 67 0 1 Yes Private
2 51676 Female 61 0 0 Yes Self-employed
3 31112 Male 80 0 1 Yes Private
4 60182 Female 49 0 0 Yes Private
5 1665 Female 79 1 0 Yes Self-employed
Residence_type avg_glucose_level bmi smoking_status stroke
1 Urban 228.69 36.6 formerly smoked 1
2 Rural 202.21 N/A never smoked 1
3 Rural 105.92 32.5 never smoked 1
4 Urban 171.23 34.4 smokes 1
5 Rural 174.12 24 never smoked 1head(veri, 5) id gender age hypertension heart_disease ever_married work_type
1 9046 Male 67 0 1 Yes Private
2 51676 Female 61 0 0 Yes Self-employed
3 31112 Male 80 0 1 Yes Private
4 60182 Female 49 0 0 Yes Private
5 1665 Female 79 1 0 Yes Self-employed
Residence_type avg_glucose_level bmi smoking_status stroke
1 Urban 228.69 36.6 formerly smoked 1
2 Rural 202.21 N/A never smoked 1
3 Rural 105.92 32.5 never smoked 1
4 Urban 171.23 34.4 smokes 1
5 Rural 174.12 24 never smoked 1Diğer verilerimizden biri olan kalp sağlığı verisinden gender(cinsiyet) ve work type(iş tipi) sütunlarına ulaşmak için gereken kodu yazalım:
table(veri$gender)
Female Male Other
2994 2115 1 table(veri$work_type)
children Govt_job Never_worked Private Self-employed
687 657 22 2925 819 Kalp sağlığı verimizden gender ve work type sütunlarındaki kategorik verilerin birlikte dağılımını gösteren kodu yazalım:
table(veri$gender,veri$work_type)
children Govt_job Never_worked Private Self-employed
Female 326 399 11 1754 504
Male 361 258 11 1170 315
Other 0 0 0 1 0Kalp sağlığı verimizden gender ve smoking status(sigara içme durumu) sütunlarındaki kategorik verilerin birlikte dağılımını gösteren kodu yazalım:
table(veri$gender,veri$smoking_status)
formerly smoked never smoked smokes Unknown
Female 477 1229 452 836
Male 407 663 337 708
Other 1 0 0 0Kalp sağlığı verimizden smoking status ve heart disease(kalp hastalığı) sütunlarındaki kategorik verilerin birlikte dağılımını gösteren kodu yazalım:
table(veri$smoking_status,veri$heart_disease)
0 1
formerly smoked 808 77
never smoked 1802 90
smokes 728 61
Unknown 1496 48Yüklediğimiz kalp sağlığı verisinin sütun isimlerini yeniden geri döndüren kodu yazalım:
colnames(veri) [1] "id" "gender" "age"
[4] "hypertension" "heart_disease" "ever_married"
[7] "work_type" "Residence_type" "avg_glucose_level"
[10] "bmi" "smoking_status" "stroke" Elimizdeki veriyi ggplot2 ile ileri seviye görselleştirelim. aes(x,y) kodunu kullanarak x değişkenine gender verisini, y değişkenine avg_glucose_level (ortalama glukoz seviyesi) atayan kodu yazalım ve verimizin içindeki sayısal değerlerin dağılımını göstermek için geom boxplot(kutu garafiği) kullanalım:
Ancak bunun için önce ggplot2 paketini yüklememiz gerekmektedir. Eğer daha önce hiç ggplot2 yüklemediyseniz, install.packages("ggplot2") yazarak paketi yükleyin.
Her kullanımdan önce library fonksiyonu ile çalışma ortamınıza yüklemelisiniz:
ggplot(data = veri, aes(x=gender,y=avg_glucose_level)) + geom_boxplot()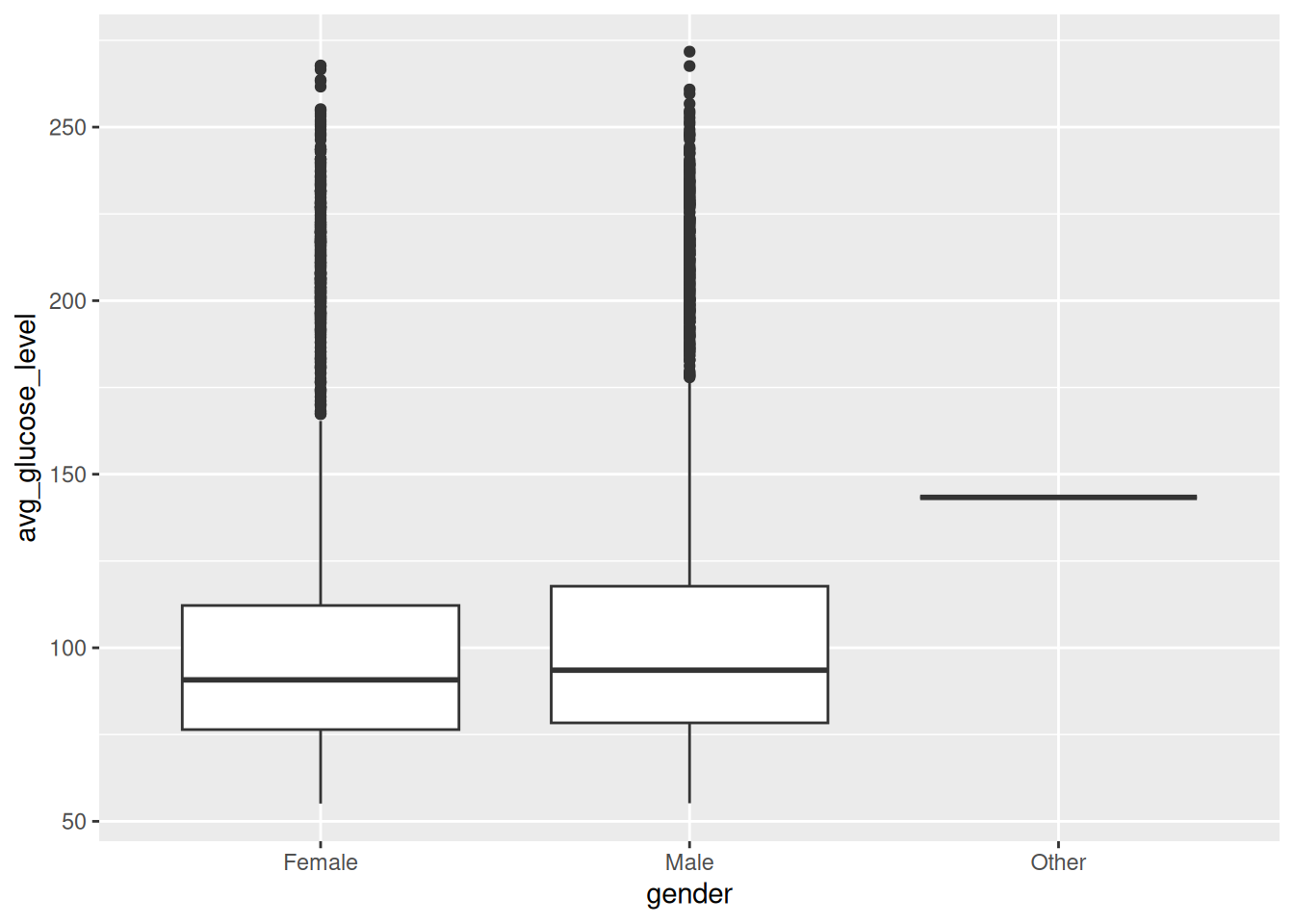
Ve bu grafiğimizi aes(color) kodu ile birlikte renklendirelim:
ggplot(data = veri, aes(x=gender,y=avg_glucose_level)) + geom_boxplot(aes(color=gender))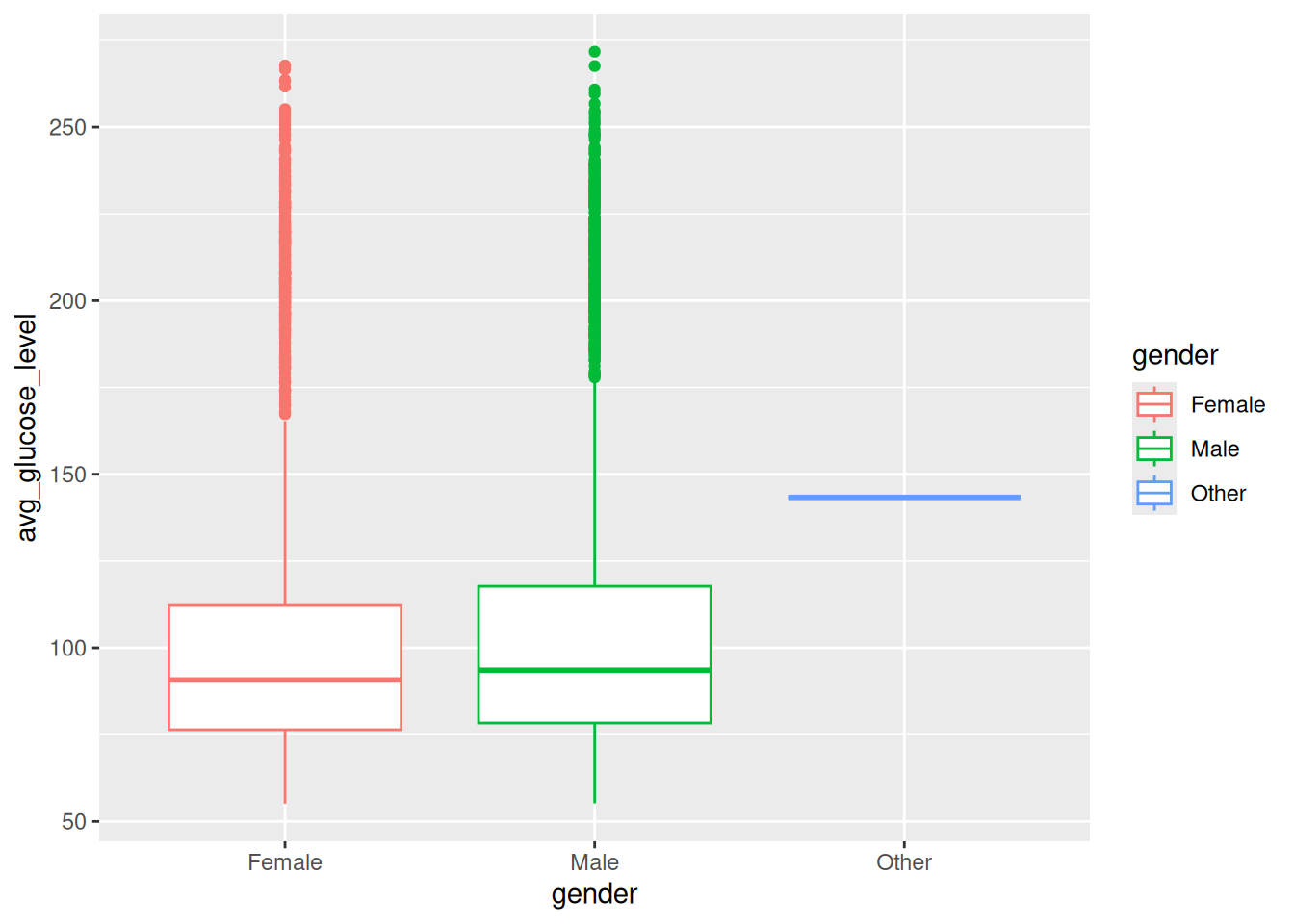
Değişkenlerimize farklı kategorilerden verileri atayıp bunun oluşturduğu tabloyu görelim:
ggplot(data = veri, aes(x=work_type,y=avg_glucose_level)) + geom_boxplot()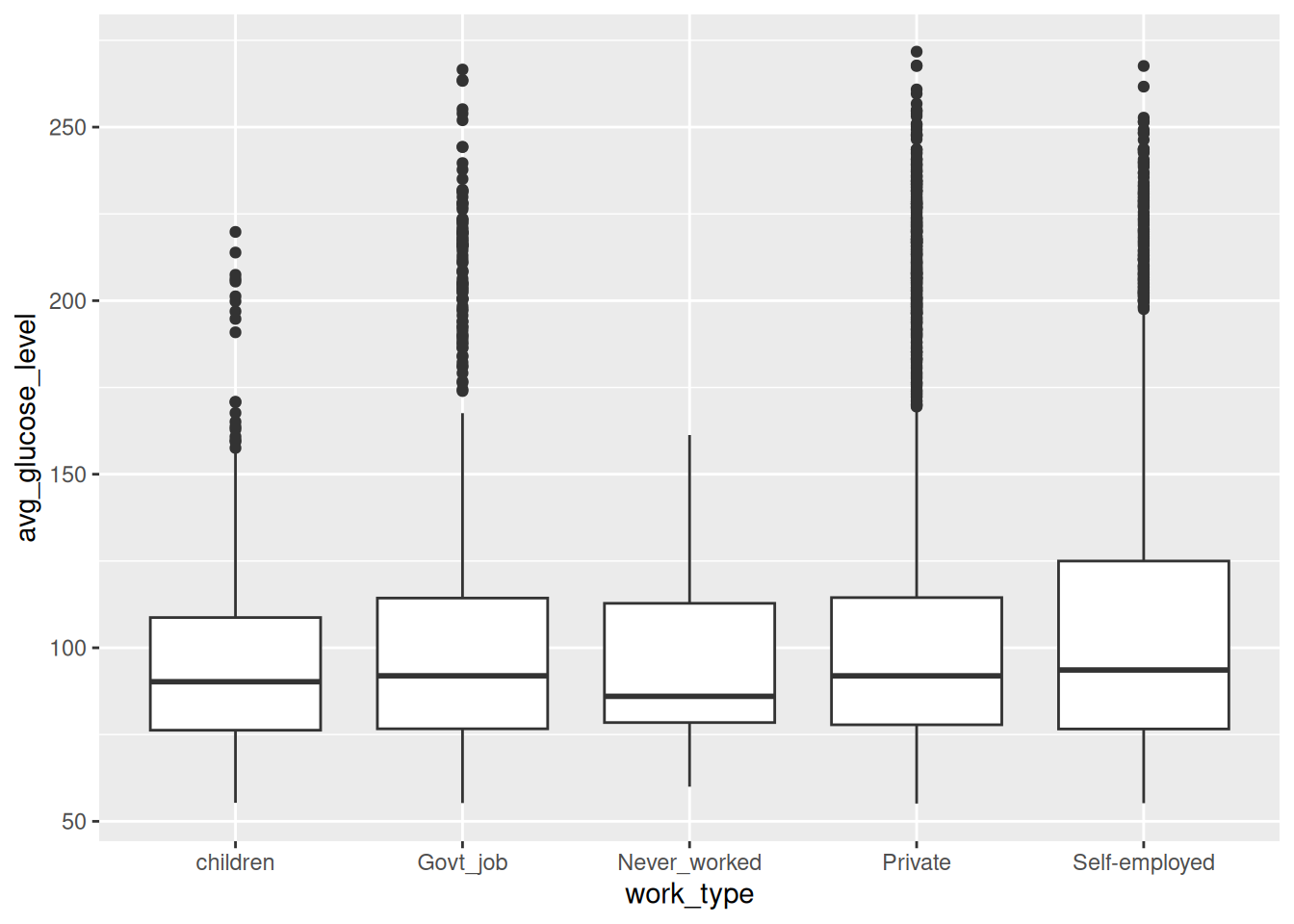
scale_color_manual fonksiyonu ile kategorilere özel olarak istediğimiz renkleri atayalım. dikkat edin, elimizde iki farklı kategori verisi var (yes, no). Bu yüzden iki farklı renk belirlemeliyiz. Daha fazla renk verirseniz, sadece ilk ikisi kullanılır:
ggplot(data = veri, aes(x=work_type,y=avg_glucose_level)) + geom_boxplot(aes(colour=ever_married))+ scale_color_manual(values = c("blue","pink"))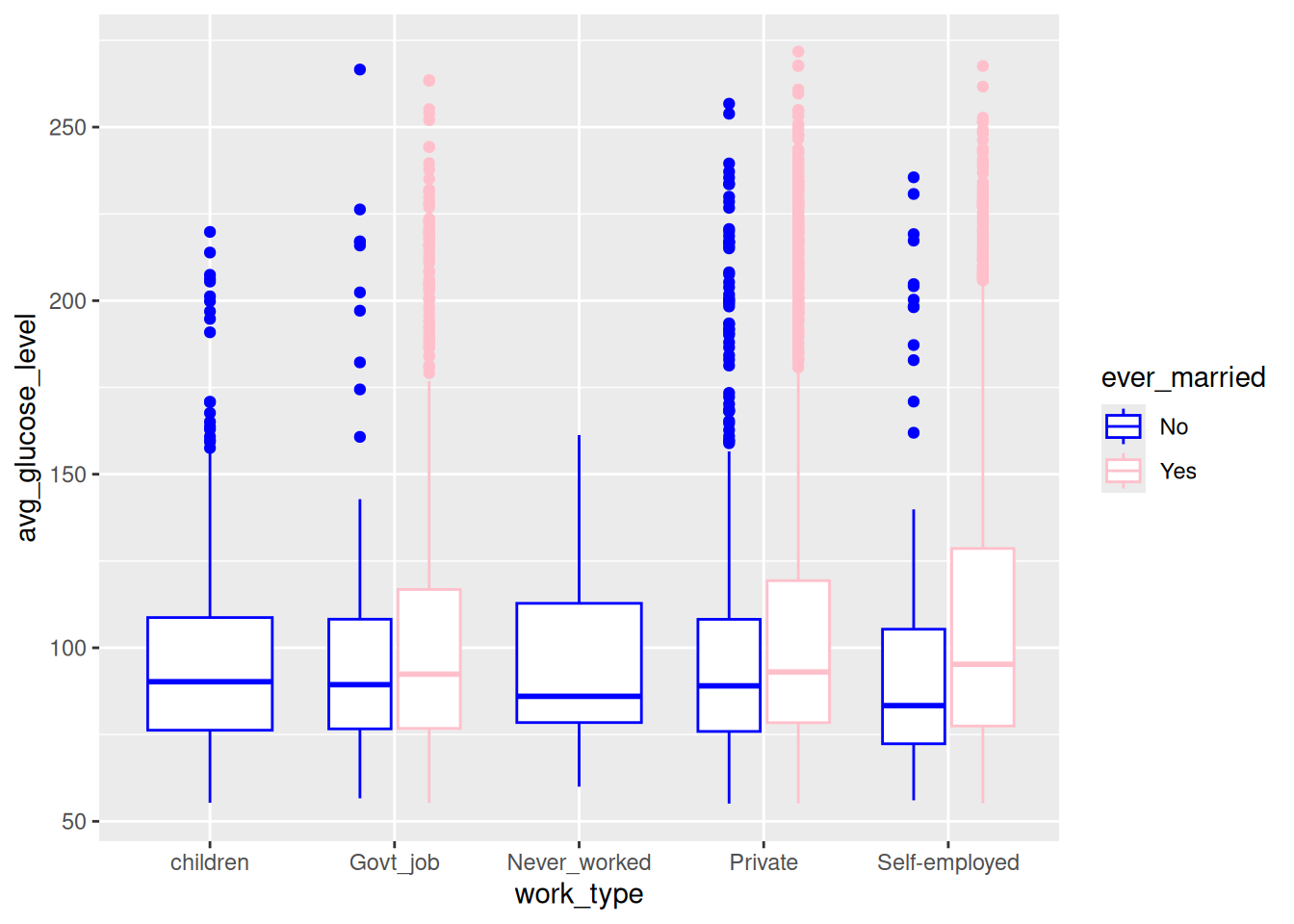
Yüklediğimiz kalp sağlığı verisinin sütun isimlerini yine geri döndüren kodu yazalım:
colnames(veri) [1] "id" "gender" "age"
[4] "hypertension" "heart_disease" "ever_married"
[7] "work_type" "Residence_type" "avg_glucose_level"
[10] "bmi" "smoking_status" "stroke" geom_histogram ile kalp sağlığı verimizin avg_glucose_level kategorisinin sıklık grafiğini oluşturan kodu yazalım:
ggplot(data = veri, aes(x = avg_glucose_level)) + geom_histogram()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.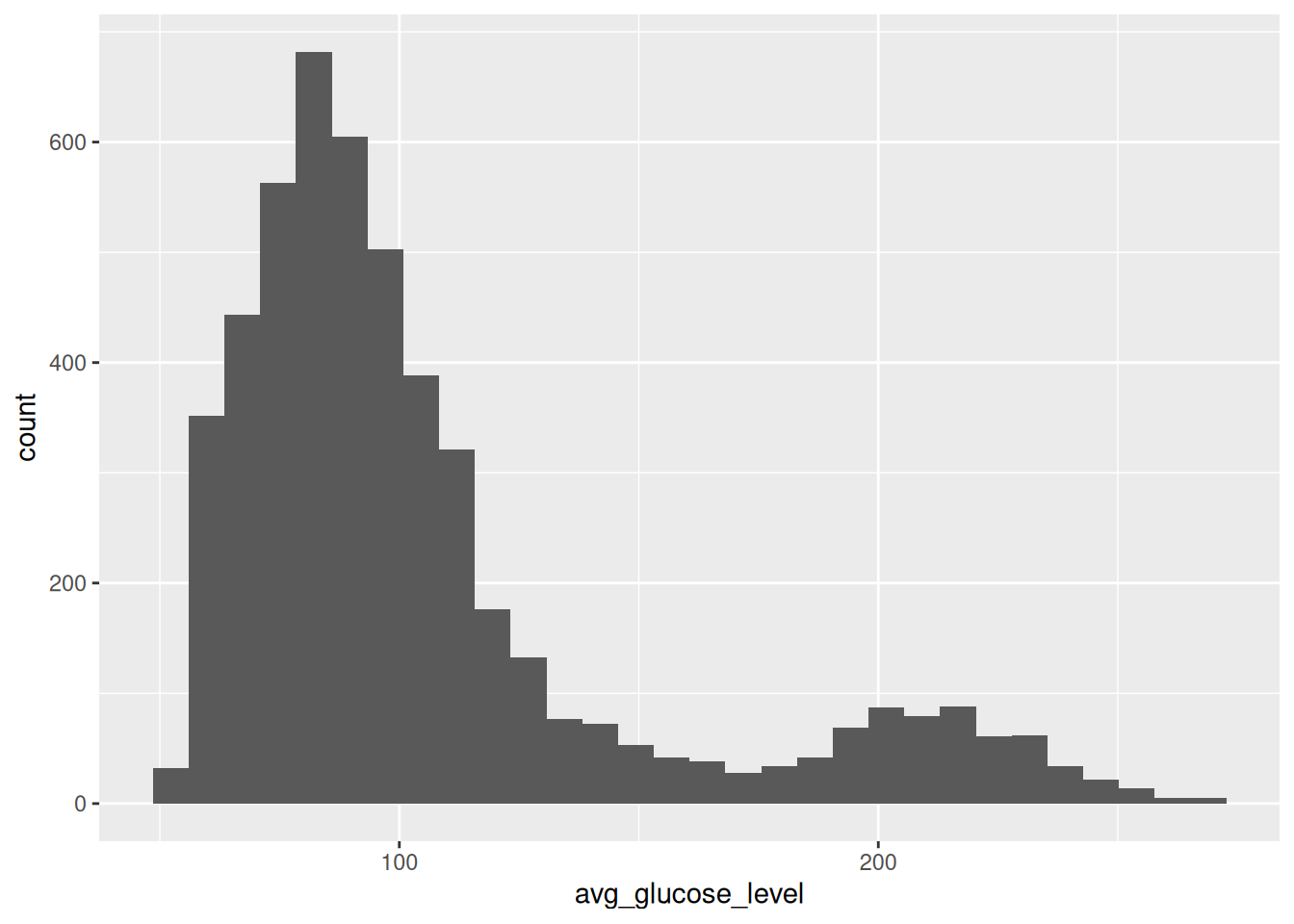
Avg_glucose_level kategorisinin gender kategorisine göre dağılımını, fill fonksiyonu kullanarak ve renk atayarak sıklık grafiğini oluşturan kodu yazalım:
ggplot(data = veri, aes(x = avg_glucose_level)) + geom_histogram(aes(fill = gender))`stat_bin()` using `bins = 30`. Pick better value `binwidth`.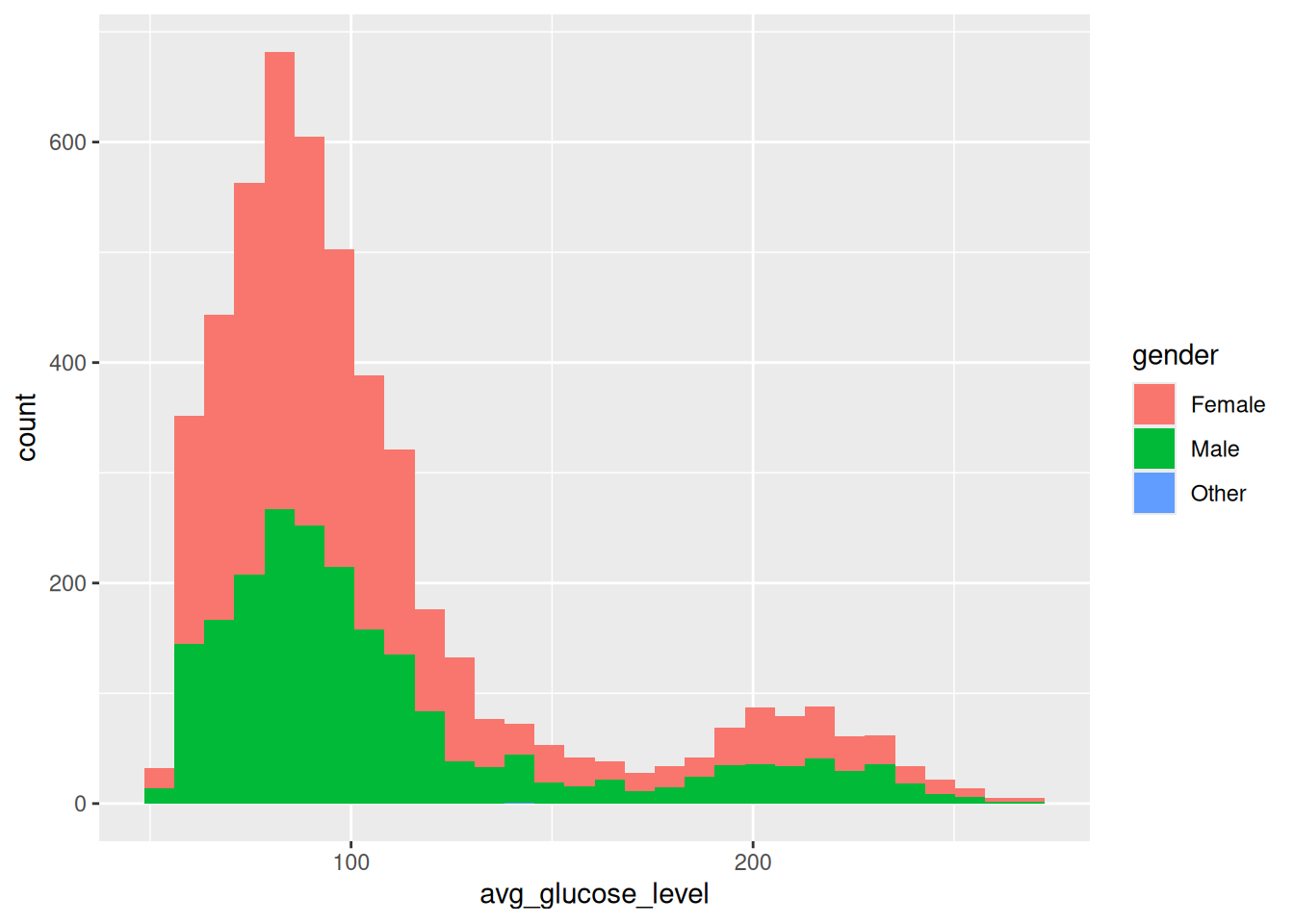
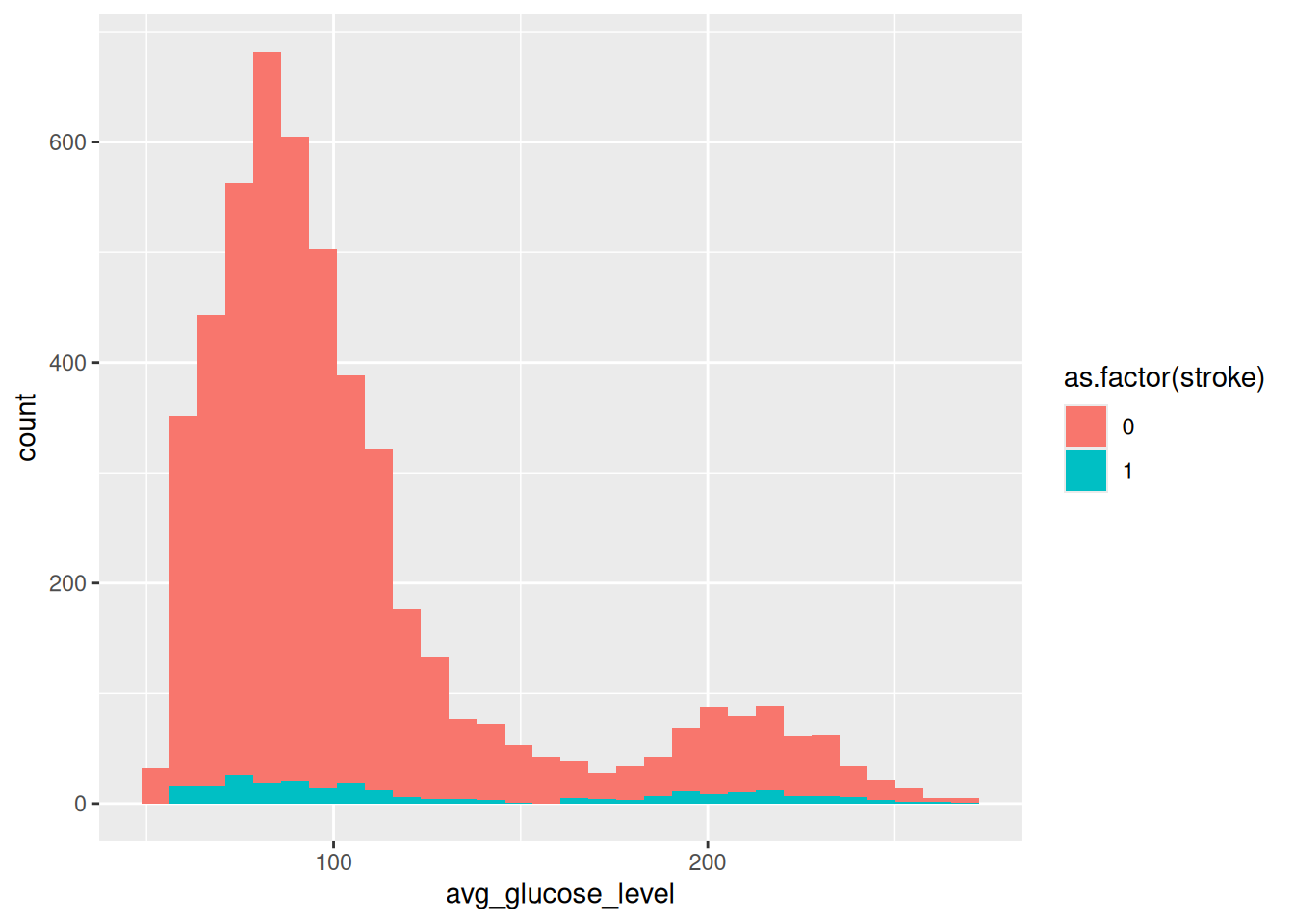
Ve son olarak avg_glucose_level kategorisine bağlı olarak as.factor fonksiyonunu kullanıp verimizdeki insanlardan hangilerinin stroke(inme) geçirdiğini gösteren kodu yazalım:
ggplot(data = veri, aes(x = avg_glucose_level)) + geom_histogram(aes(fill = as.factor(stroke)))`stat_bin()` using `bins = 30`. Pick better value `binwidth`.